We use cookies to enhance your browsing experience, serve personalized ads or content, and analyze our traffic. By clicking "Accept All", you consent to our use of cookies.
Customize Consent Preferences
We use cookies to help you navigate efficiently and perform certain functions. You will find detailed information about all cookies under each consent category below.
The cookies that are categorized as "Necessary" are stored on your browser as they are essential for enabling the basic functionalities of the site. ...
Always Active
Necessary cookies are required to enable the basic features of this site, such as providing secure log-in or adjusting your consent preferences. These cookies do not store any personally identifiable data.
No cookies to display.
Functional cookies help perform certain functionalities like sharing the content of the website on social media platforms, collecting feedback, and other third-party features.
No cookies to display.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics such as the number of visitors, bounce rate, traffic source, etc.
No cookies to display.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
No cookies to display.
Advertisement cookies are used to provide visitors with customized advertisements based on the pages you visited previously and to analyze the effectiveness of the ad campaigns.
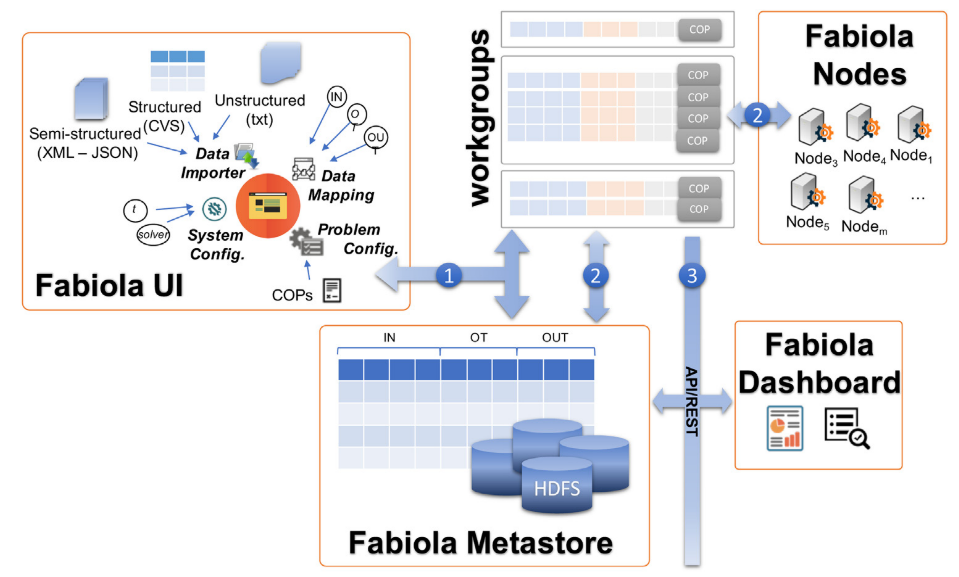
FABIOLA enables Constraint Optimisation Problems (COPs) in large datasets by using Big Data techonologies in a user-friendly way. It enables to (1) create COP models; (2) integrate different data sources; (3) map dataset attributes to COP-model variables; (4) solve the COPs in a distributed way, and (5) perform advanced queries on the results.
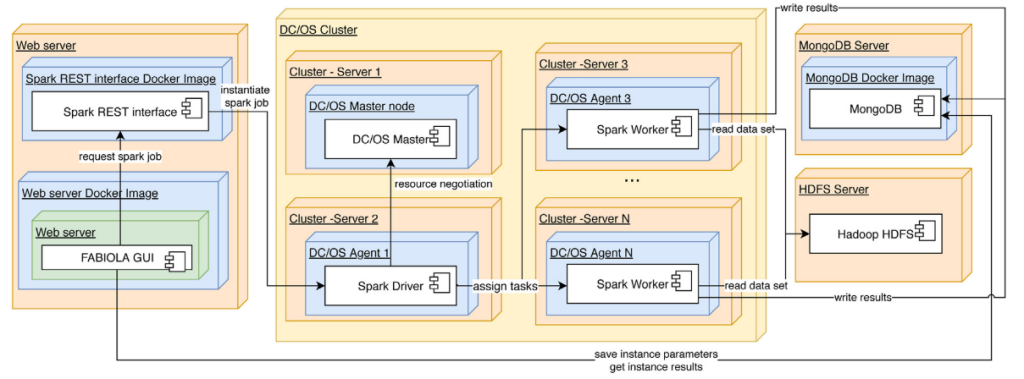
The FABIOLA Big Data layer is based on Apache Spark. The most recent version relies on the COP solver choco-solver. The user interface is composed of a REST API implemented in NodeJS, and a front-end based on AngularJS.
The architecture fullfils the principles of low coupling and high cohesion. The communication among the different modules which compose this architecture is performed through REST APIs. In this way, all components are highly independent, and modifying or scaling any of them causes a low impact on the others.
The deployment of the Big Data layer is performed in a DC/OS cluster. It provides a highly elastic environment, since extending or reducing the amount of availables nodes is a very easy and transparent process. On the other hand, the backend and backend were deployed with Docker images.
A quick tour
Next, a quick tour on the features of this tool is presented.
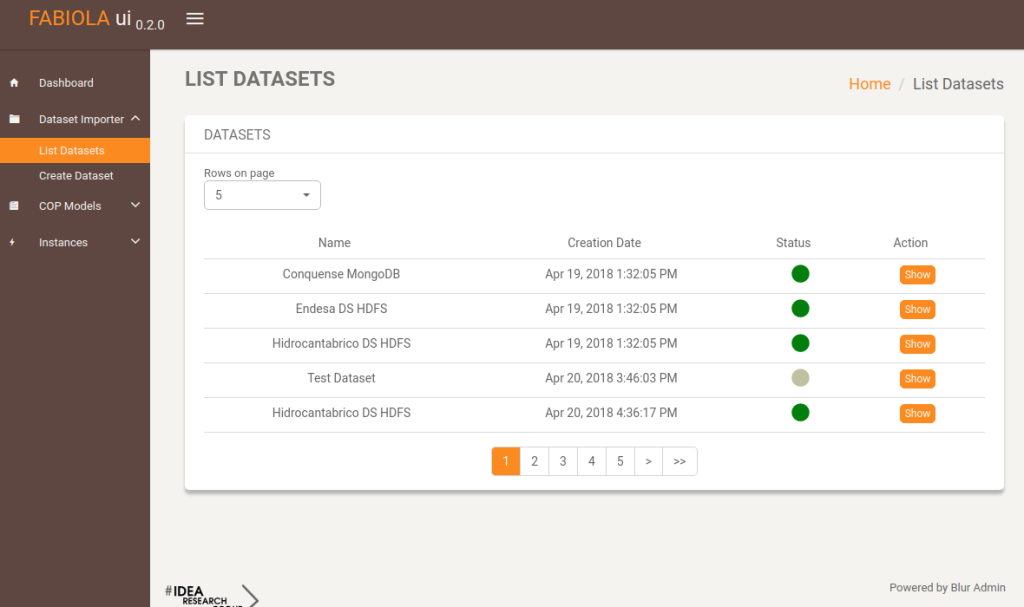
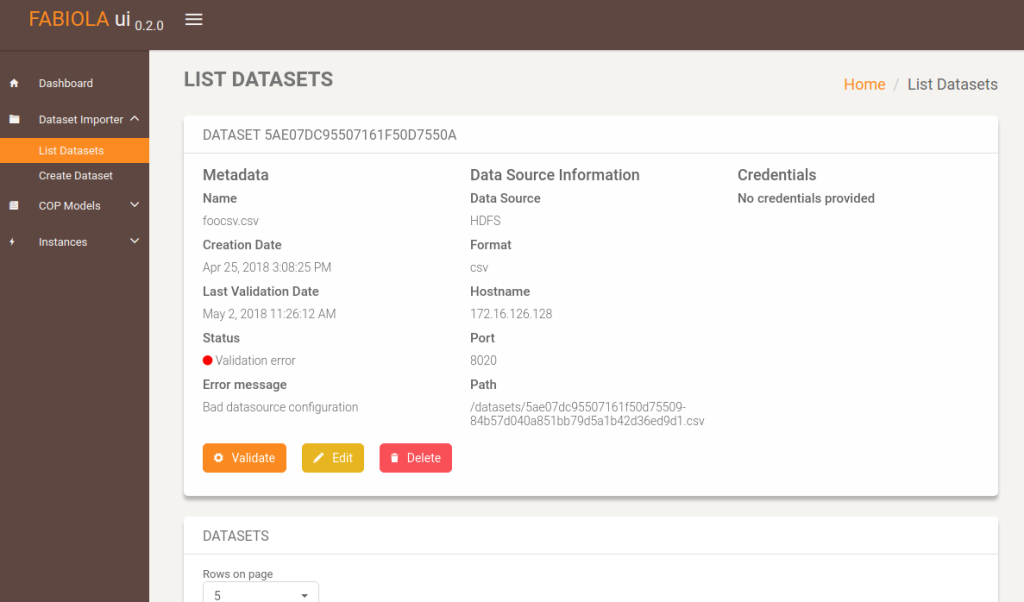
This is the view where users can see their datasets.
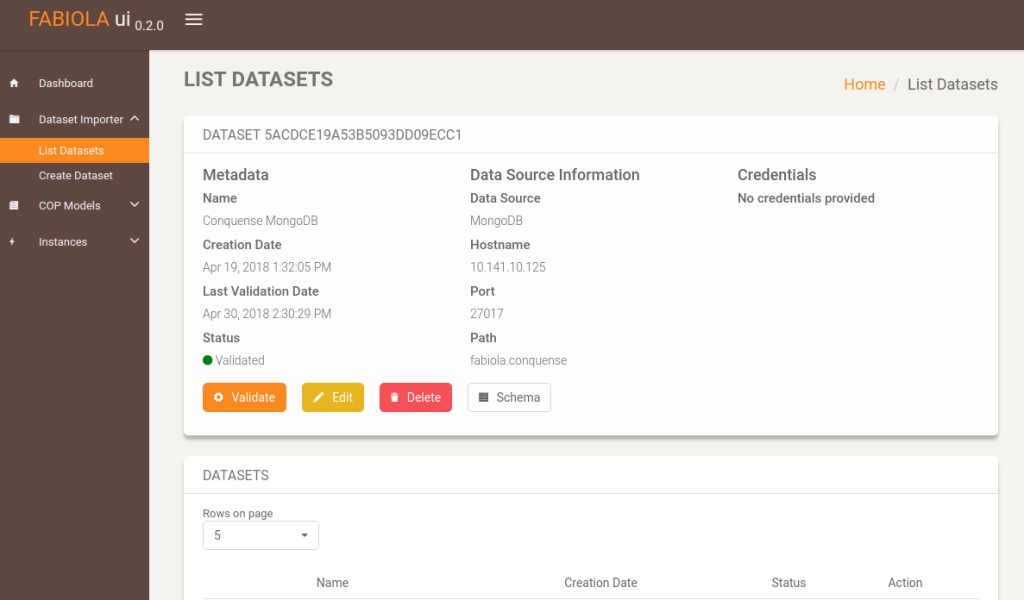
By clicking the show button on a dataset, the user will get a detailed view on the features of the dataset. Note the validate button. By clicking that, the system will query such dataset and check if it correct. If so, the status will be validated.
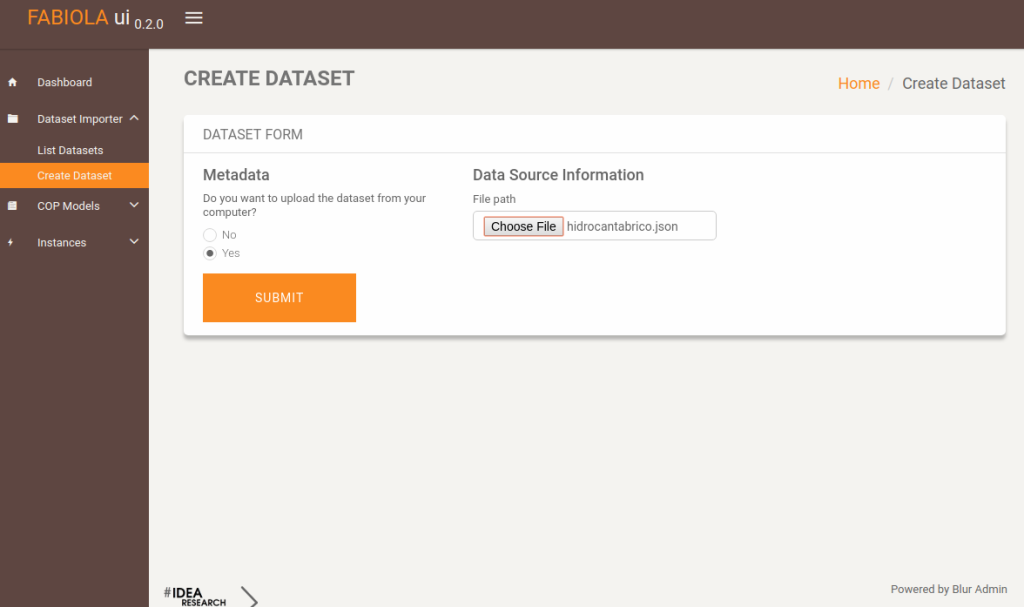
Creating a dataset is very simple. Users might import their datasets from their own data sources. FABIOLA can read from several storage systems such as HDFS and MongoDB.
Users also might upload a dataset from their own computer.
Creating COP Models
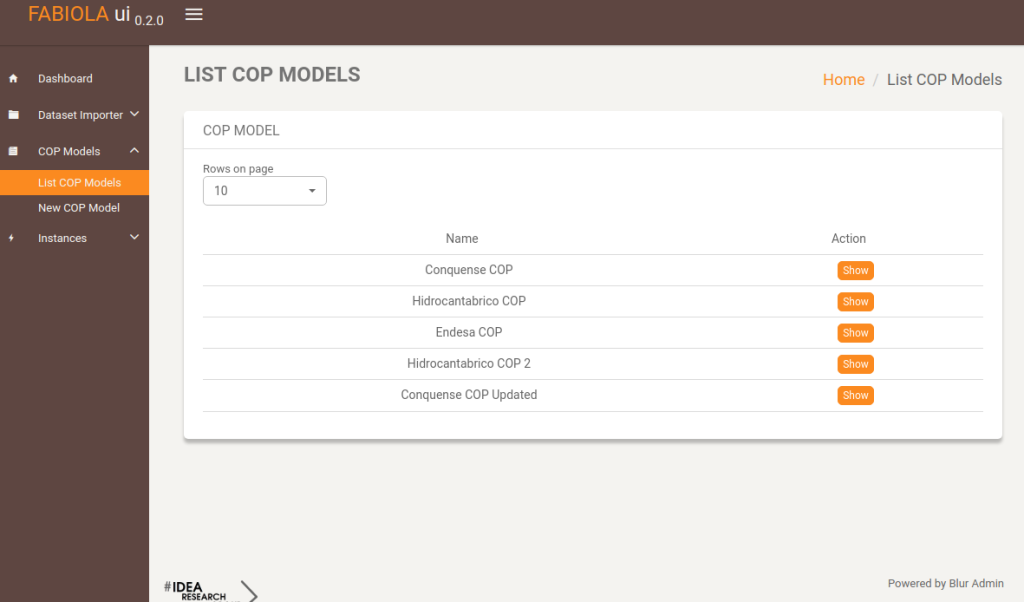
In this view, the user can get a list of all the COP models defined by them.
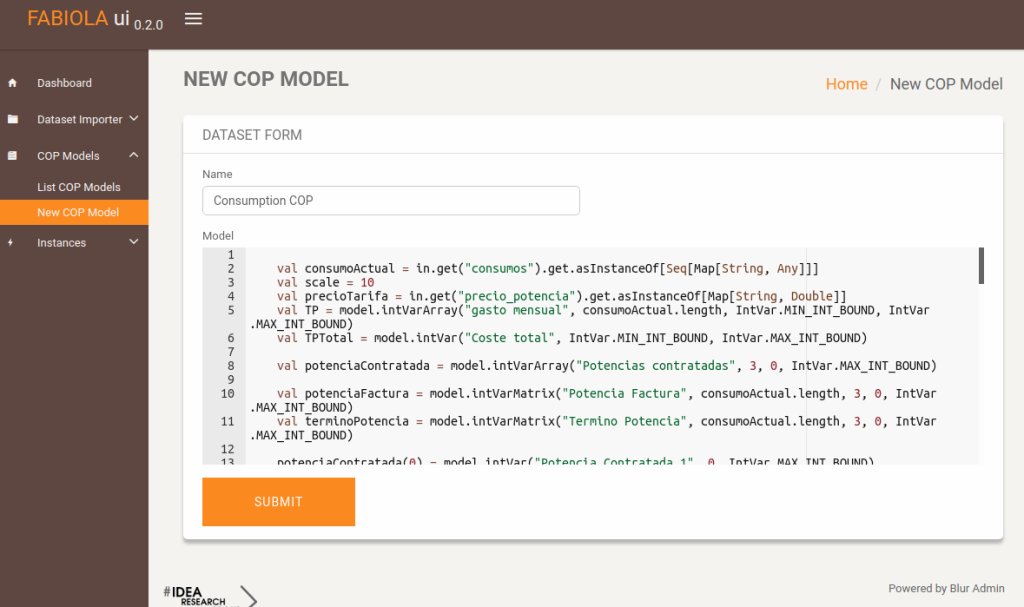
This is an example of a COP model. These are defined in Scala by using the library choco-solver.
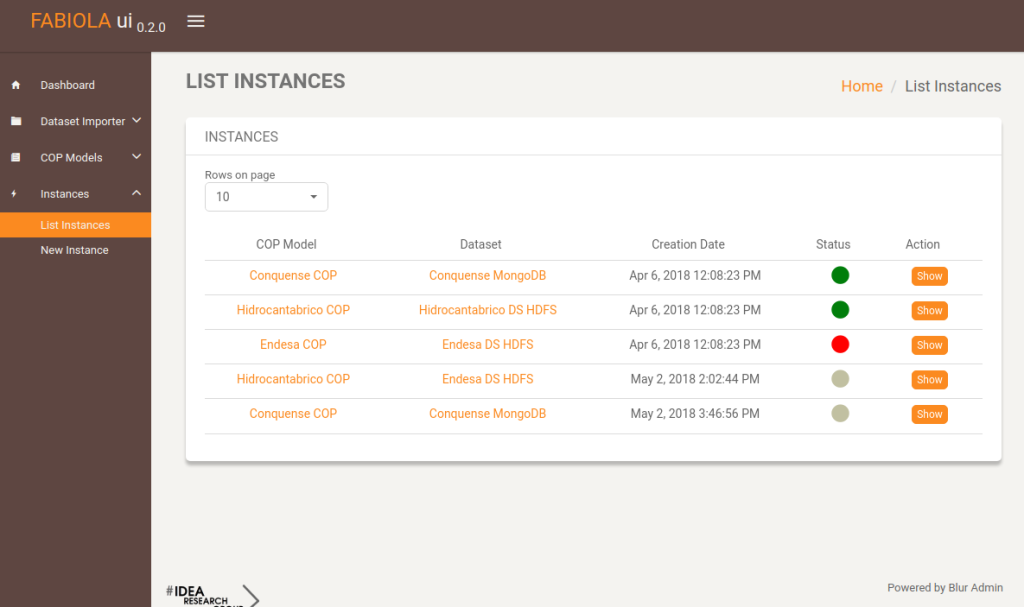
Managing instances
In this view, all instances are listed. An instance represents an execution, and is related to a dataset and a COP model.
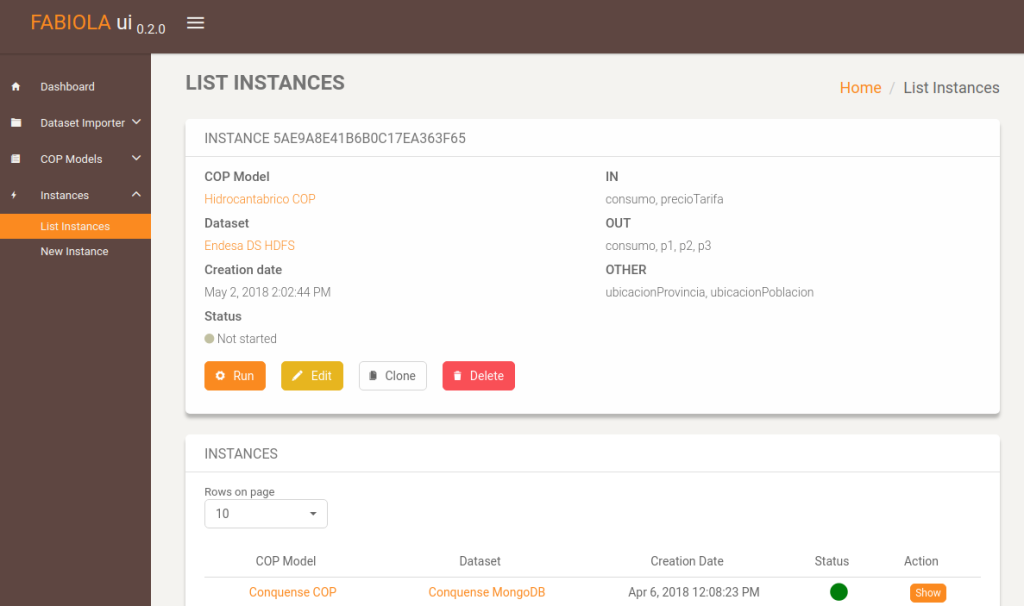
This is a detailed view of an instance that has not been executed yet.
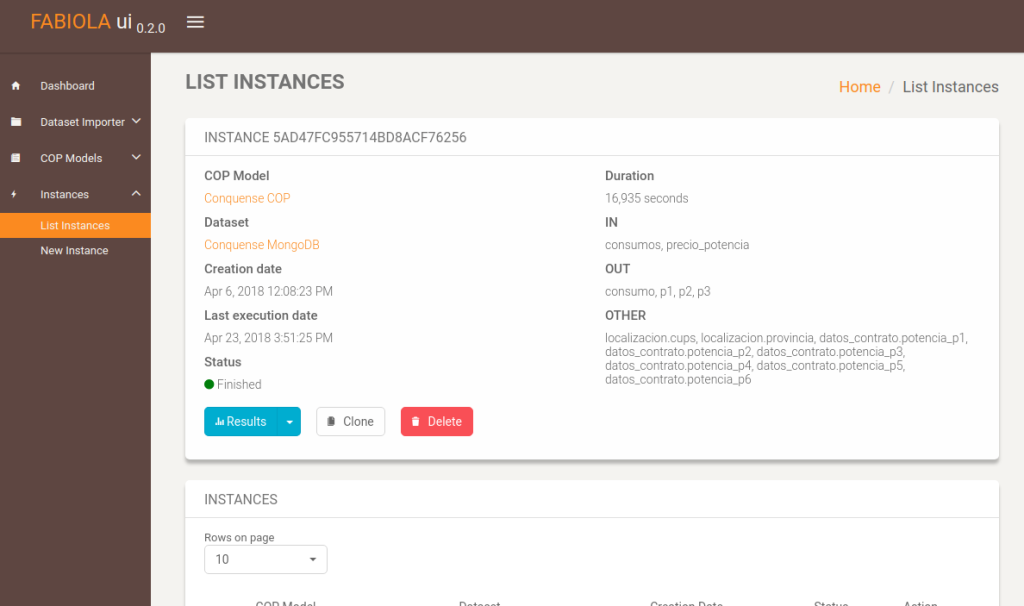
This is a detailed view of an instance that has been executed. By clicking the results button, the user can access to the querying tool of FABIOLA.
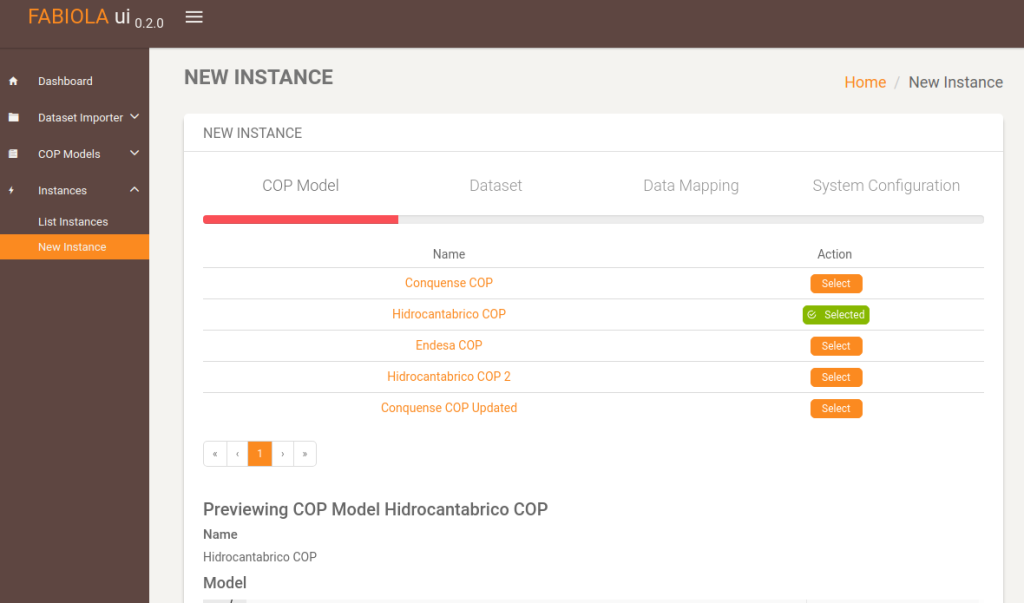
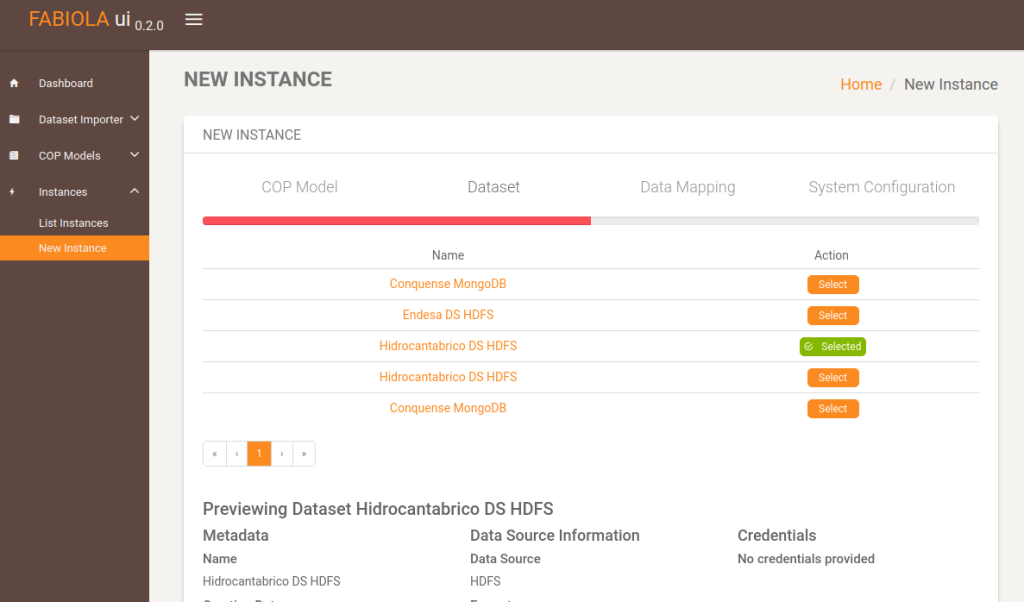
This is the creation process of a new instance. First, the COP model must be selected.
The next step is to select the dataset to be employed in this instance.
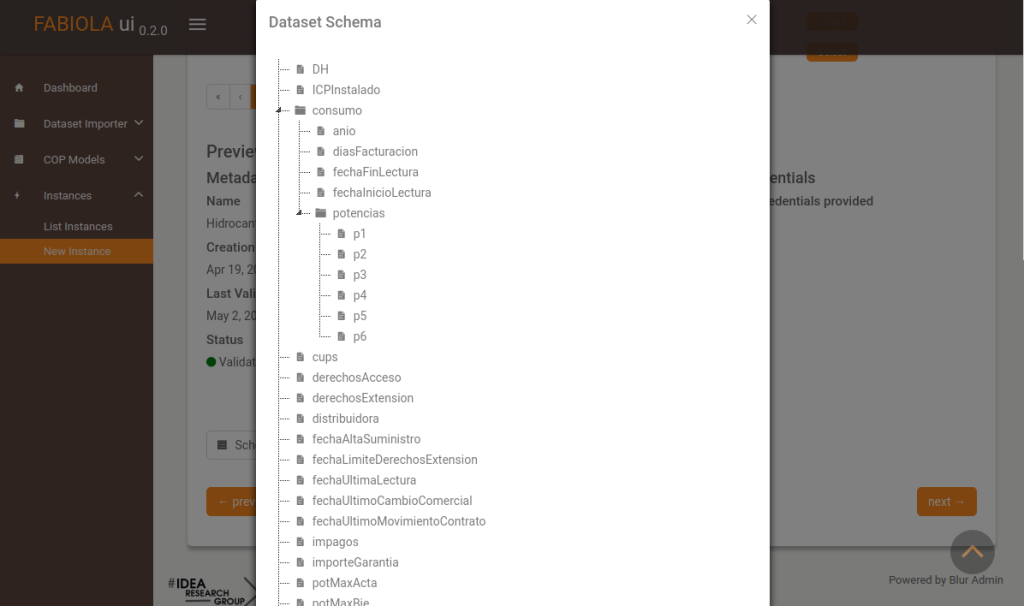
There is a preview view for each dataset. Here, users can get details about its schema.
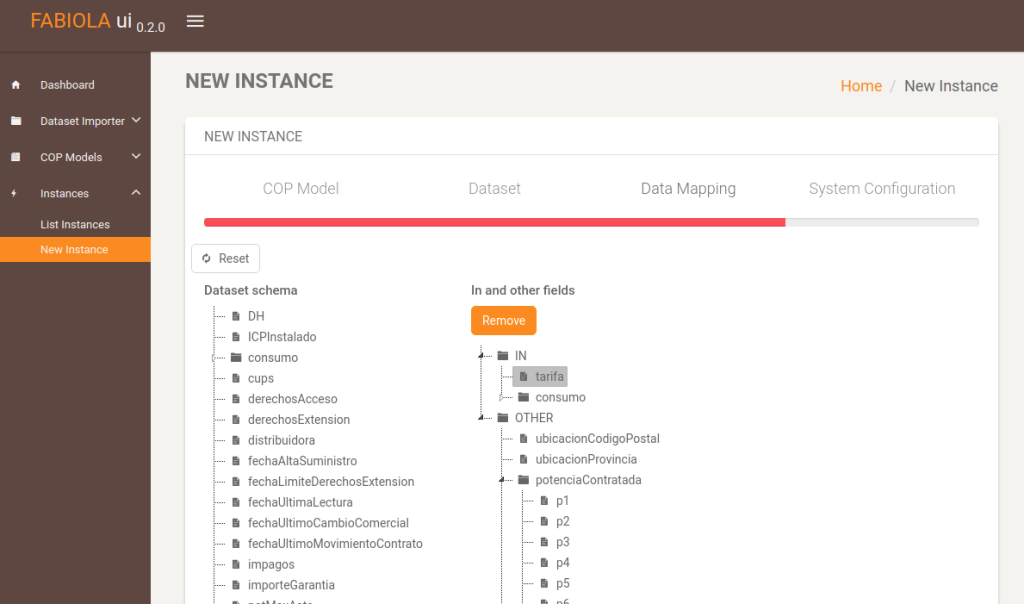
Once the COP model and dataset have been selected, the user must map the dataset attributes to the COP variables. As explained in [1], there are three types of variables: IN, OTHER, and OUT. FABIOLA enables to perform this napping in a drag-and-drop basis.
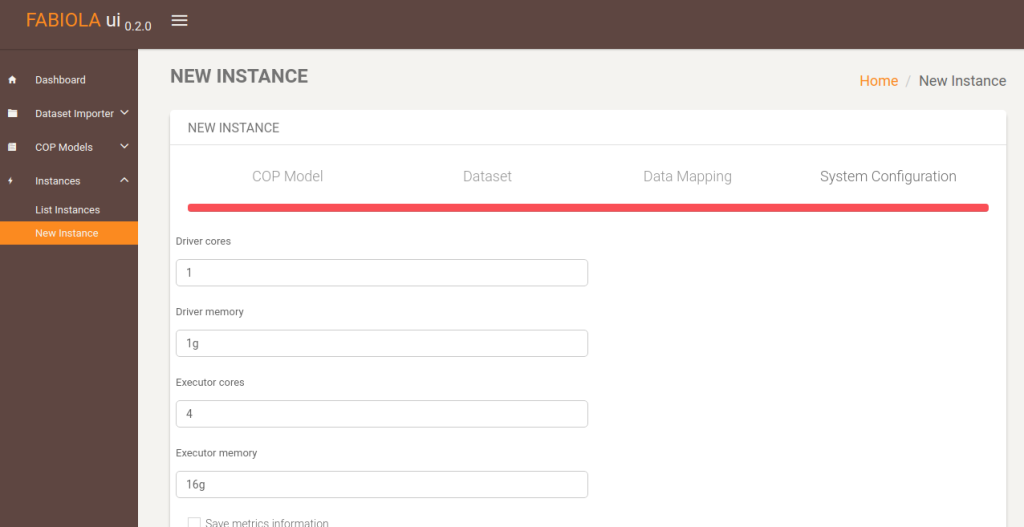
The last step before creating the instance, is to select the desired configuration parameters for the cluster.
Querying results
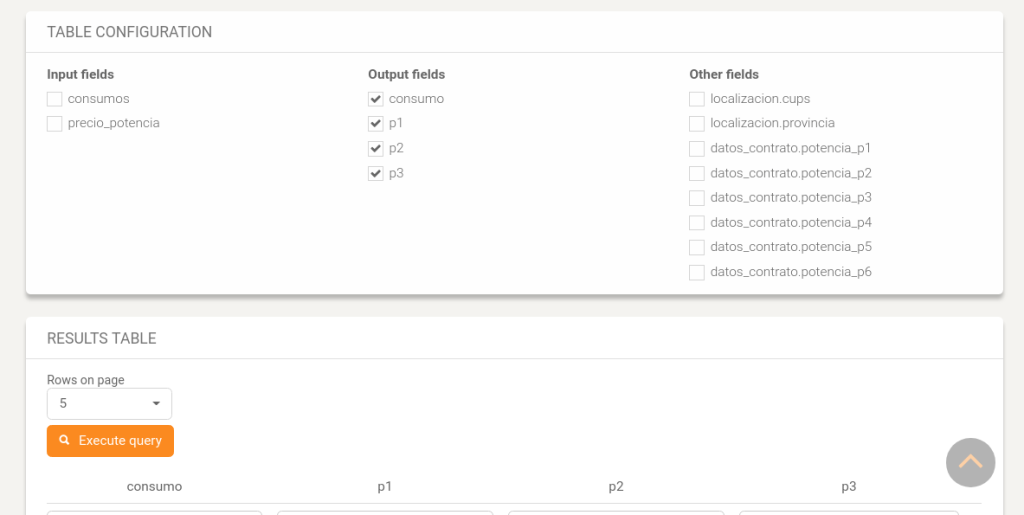
This is an example of the querying tool of FABIOLA. In this view, user can select the fields to query. Output fields are those generated by the COP and defined by the user during the data mapping process.
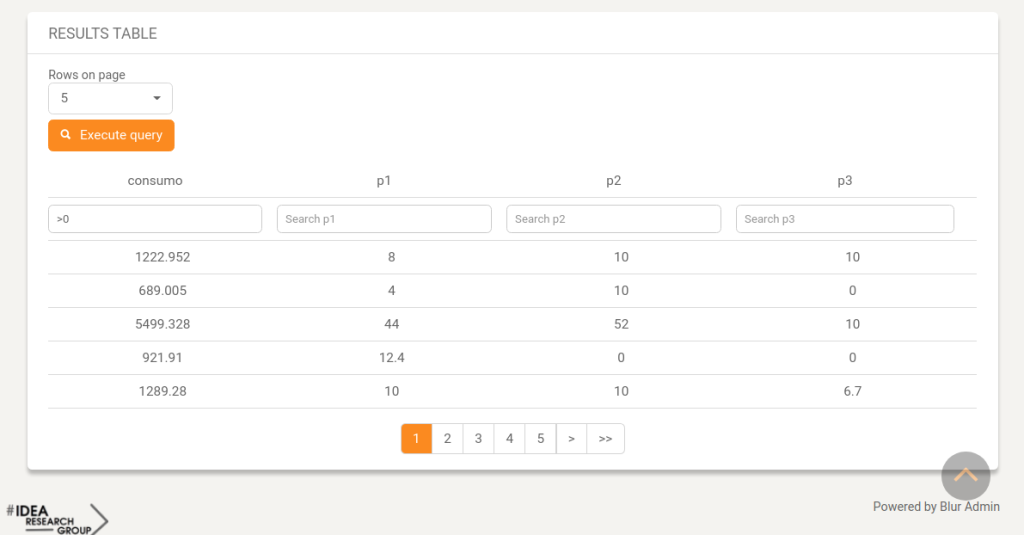
Example of a tabular view.
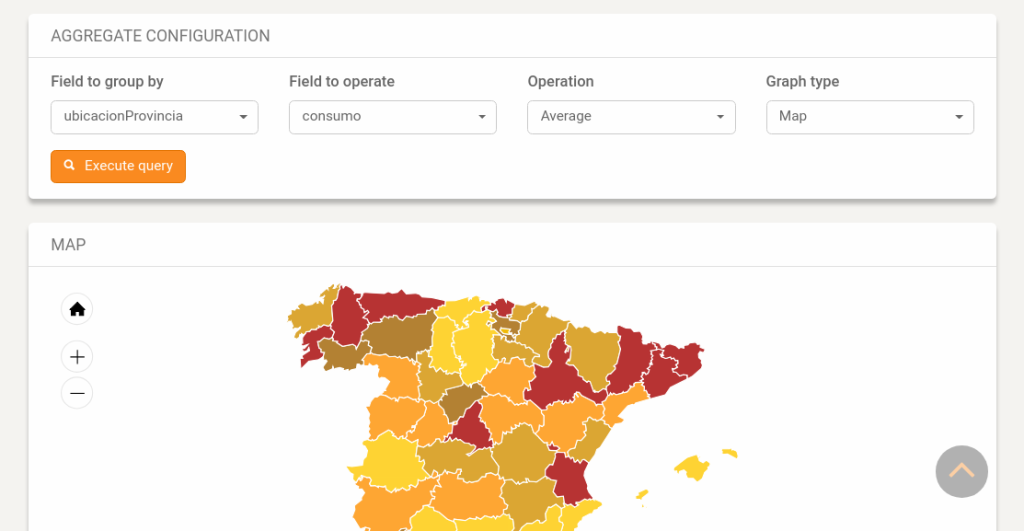
FABIOLA also supports aggregation operators. User can choose data attributes and operators, and depict the aggregated data in tables or maps.
Results
The proposal was tested in an industrial scenario. Several Spanish electricity companies wanted to get the optimal power which each of their customers might contract in order to minimise their consumption. Our study [1] demonstrated that distributed COPs dastrically improved the global execution time. Including more worker nodes might improve the performance.
[1] Valencia-Parra, Á., Varela-Vaca, Á. J., Parody, L., & Gómez-López, M. T. (2020). Unleashing Constraint Optimisation Problem Solving in Big Data Environments. Journal of Computational Science, 45, 101180. https://doi.org/10.1016/j.jocs.2020.101180